Robust AI-Generated Image Detection
Developed ROGER, a robust, multi-modal model for AI-generated image detection that outperforms a state of the art model (SPAI) on augmented real-world images.
More About the Project
Python | PyTorch | Selenium | Deep Learning
Technical Report
My Contributions
Data Pipeline and Robustness Testing
Contributed to creating challenging datasets that simulate real-world image modifications to test model robustness.
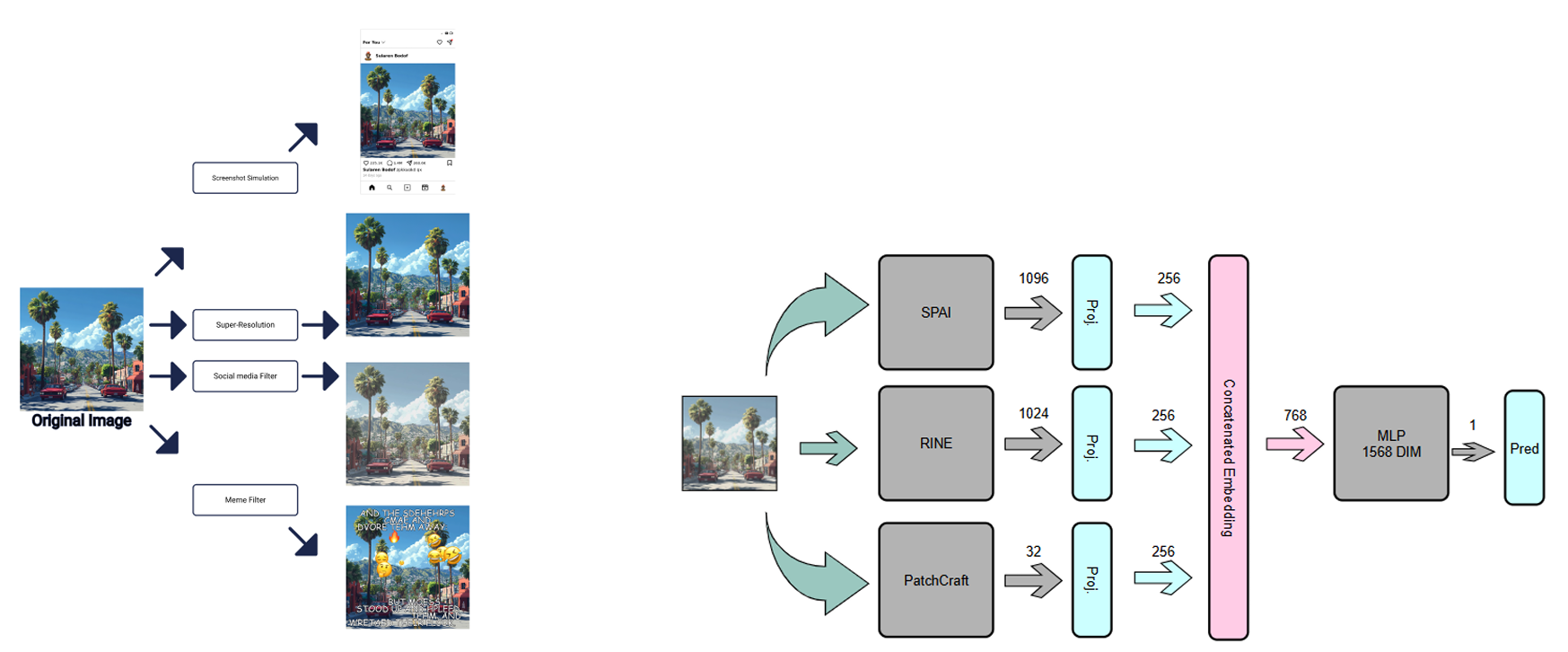
Specifically implemented the social media screenshot simulation dataset, using Selenium to dynamically inject images into a custom HTML template.
Randomized numerous dynamic HTML elements (like/comment counts, usernames, captions) to ensure each generated screenshot was unique.
Model Development (ROGER)
Co-developed the ROGER (RObust AI-GEnerated image Recognizer) model to address the weaknesses of SPAI.
Designed and implemented the integrated model approach, a multi-modal architecture combining three complementary AID models.
Extracted and concatenated embeddings from SPAI (spectral), RINE (mid-level), and PatchCraft (texture) into a unified 768-dimensional feature vector.
Trained the final MLP classification head (2-layer, 1536-unit) on the combined embeddings to produce a single, robust prediction.
Performance Evaluation
Successfully reproduced the original SPAI paper’s results, verifying its baseline performance and high reproducibility.
Demonstrated that the created ROGER model significantly outperforms the baseline SPAI on all four challenging real-world datasets.